| Pandas数据分析实战(1) | 您所在的位置:网站首页 › Pandas数据分析实战超强案例 百度云 › Pandas数据分析实战(1) |
Pandas数据分析实战(1)
|
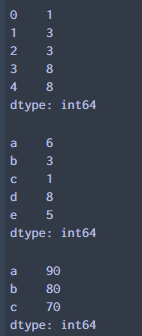
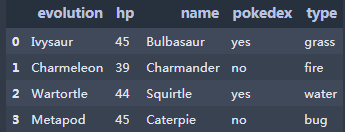
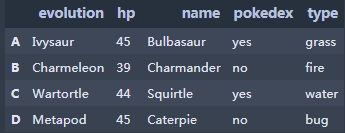
Python在数据处理和准备一直做得很好,但在数据分析和建模方面就差一些。pandas帮助填 补了这一空白,使您能够在Python中执行整个数据分析工作流程,而不必切换到更特定于领域的语 言,如R。pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。pandas是Python进行数据分析的必备高级工具。 pandas的主要数据结构是 Series(一维数据)与 DataFrame (二维数据),这两种数据结构足以处理 金融、统计、社会科学、工程等领域里的大多数案例。处理数据一般分为四个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。 **数据来源与下载:https://www.heywhale.com/mw/dataset/59e715b76d213335f38d4507 1.创建数组和数据框 1.1Series用列表生成 Series时,Pandas 默认自动生成整数索引,也可以指定索引 s1 = pd.Series(np.random.randint(1,10,5))#默认自动生成整数索引 s2 = pd.Series(np.random.randint(1,10,5),index=list('abcde'))#指定行索引 s3 = pd.Series({'a':90,'b':80,'c':70})#采用字典方式创建,键为行索引 display(s1, s2, s3)输出: Dataframe是由多种类型的列构成的二维标签数据结构,类似Excel\SQL 表,或Series对象的字典 pokemon = pd.DataFrame({'evolution':['Ivysaur','Charmeleon','Wartortle','Metapod'], "hp": [45, 39, 44, 45], "name": ['Bulbasaur', 'Charmander','Squirtle','Caterpie'], "pokedex": ['yes', 'no','yes','no'], "type": ['grass', 'fire', 'water', 'bug']}) pokemon.rename(index = {0:'A',1:'B',2:'C',3:'D',4:'E'})#修改行索引 #修改列索引将index改为columns输出: chipotle快餐店的订单的样本数据(chipotle.tsv),具体字段说明如下: 字段名称解释说明order_id订单编号quantity数量item_name产品名称choice_description产品描述 2.1数据输入 import pandas as pd chipo = pd.read_csv('chipotle.tsv', sep = '\t',header = [0]) #若数据无列索引,则header = None #若数据存在行索引,则index_col = 0,可以指定行索引 #若文件为csv,默认分隔符为逗号,则sep = ',' 2.2数据查看1.查看数据前10行 chipo.head(10)输出: 输出: 输出: 输出: 输出: 输出: 输出: 输出: 1.查看产品名称这一列,返回数据为Series chipo.item_name chipo['item_name']输出: 输出: 输出: 输出: 输出: 输出: 输出: 今天先写到这里,我们下期再见O(∩_∩)O **整理课件不易,走过路过觉得课程内容不错,请帮忙点赞、收藏!Thanks♪(・ω・)ノ****如需转载,请注明出处 |
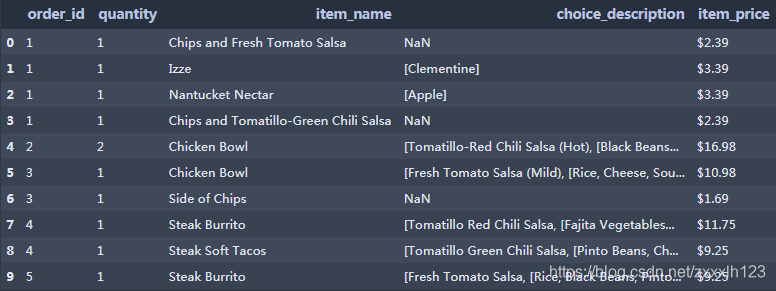 2.查看数据后10行
2.查看数据后10行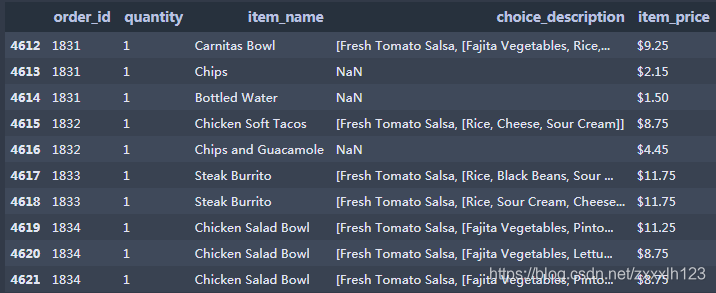 3.查看形状,数据的行数和列数,输出(行数,列数)
3.查看形状,数据的行数和列数,输出(行数,列数) 4.行索引,从0开始到4622(不包含),步长为1
4.行索引,从0开始到4622(不包含),步长为1 5.列索引,各列的名称
5.列索引,各列的名称 6.对象值,二维ndarray-NumPy数据结构
6.对象值,二维ndarray-NumPy数据结构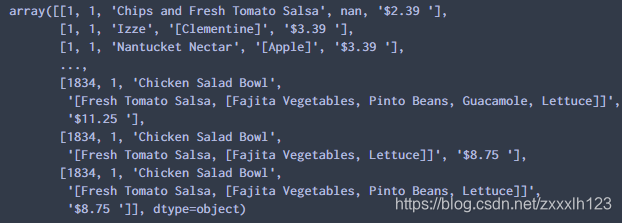 7.查看数值型列的数据汇总统计,输出count计数、mean平均值、std标准差、min最小值、25%第一四分位数、50%中位数、75%第三四分位数、max最大值
7.查看数值型列的数据汇总统计,输出count计数、mean平均值、std标准差、min最小值、25%第一四分位数、50%中位数、75%第三四分位数、max最大值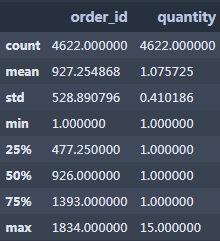 8.查看列索引(Columns)、数据类型(Dtype)、缺失值个数(Non-Null Count)和内存信息(memery usage)
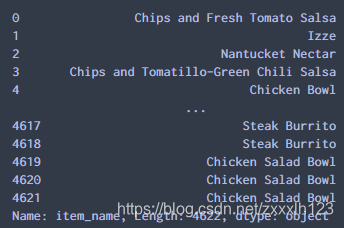
8.查看列索引(Columns)、数据类型(Dtype)、缺失值个数(Non-Null Count)和内存信息(memery usage)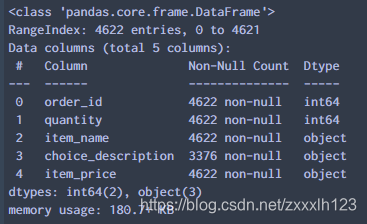
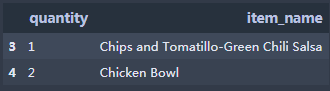
 2.查看产品名称及数量这两列,返回数据为DataFrame
2.查看产品名称及数量这两列,返回数据为DataFrame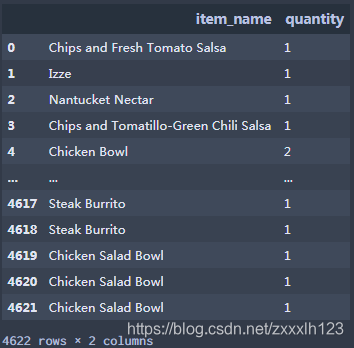 3.查看行索引从3开始到10结束(不包含)
3.查看行索引从3开始到10结束(不包含)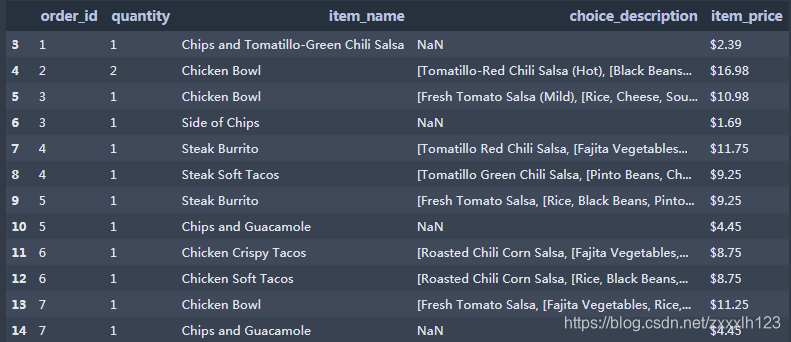 4.查看销售数量大于5的商品订单信息
4.查看销售数量大于5的商品订单信息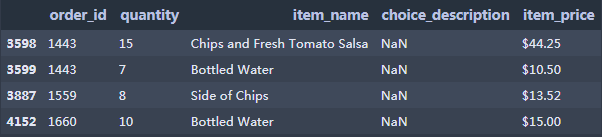 5.查看销售数量大于50,商品名称为’Bottled Water’的订单信息
5.查看销售数量大于50,商品名称为’Bottled Water’的订单信息 6.按位置选择数据
6.按位置选择数据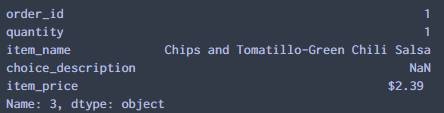
 7.新增一列remark,并给列中元素赋值
7.新增一列remark,并给列中元素赋值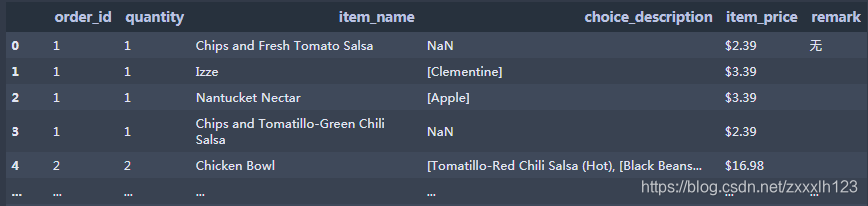
【本文地址】